如果不說明一下 YOLO 的運作概念,對於如何調整 YOLO 參數將會是一籌莫展,所以今天就來說明一下影像辨識的基礎概念一直到 YOLO 的運作概念
人工智慧、機器學習與深度學習
影像識別其實是深度學習的一種應用,而深度學習是機器學習的一個子集,機器學習則是包含在人工智慧這個大範圍內。人工智慧當初的發想是希望透過計算機來取代人類的許多能力,可以包含五感,如視覺、聽覺、嗅覺、味覺和觸-壓覺五種感官的感知,在透過大腦的思考來進行判斷,廣義上可以這樣思考。而機器學習則勢將這樣的想法具體化成
這些學習的目的都是為了讓機器可以協助人類進行判斷,進而找出最佳答案,那現在問題來了,什麼是答案?簡單來分,答案有兩種,比方說,明天會不會下雨,可以說 80% 會下雨,或是說會下雨,專業一點的說法是一種是離散,一種是類別。
以下以 BMI 的標準來想像所謂的機器學習,假設我們不知道 BMI 的公式,而我們的到這樣一張表格,體重狀況就是的答案(標籤)也就是我們要預測的目標,而 體重、 身高、 性別、年紀,就是特徵,現在就是要透過這些特徵來找出第四筆資料應該是什麼內容?很明顯的,這就是一個監督式機器學習,而且是屬於類別形的判斷。機器學習的過程希望找出一個函數(模型),讓我們將體重、 身高、 性別、年紀等特徵輸入進去後,可以得到一個結果,可能是就是正常、過重或過輕。
| 體重狀況 | 體重 | 身高 | 性別 | 年紀 |
|---|---|---|---|---|
| 正常 | 70 | 178 | 男 | 50 |
| 過重 | 77 | 165 | 女 | 40 |
| 過輕 | 45 | 170 | 男 | 30 |
| ? | 60 | 168 | 女 | 50 |
於是就有人想出,那能不能把整個判斷式想成以下這個方程式,那問題就變得很簡單,就是只要找出權重值就好。
$h_w(x)=w_0 x_0 + w_1 x_1 + \dots + w_d x_d=\sum_{i=0}^{D} w_d x_d$
其中:
面對上面這樣的問題,很明顯的我們需要做很多資料前處理的動作,比方說把男、女,轉換成數值,當然,輸出的結果(體重狀況)也應該是個數值。這就是一個很典型的機器學習的例子,找出特徵,處理標籤等等的,相信有很多人都可以發現,年紀似乎不是 BMI 計算的數值內容,性別也不是,這就是所謂特徵的相關性的問題,特徵與標籤相關性的問題,把所有搞機器學習的人搞瘋了,因為要進行機器學習之前必須先找出特徵,這導致很多機器學習的研究停滯不前了。後來,竟然有人想說,那是不是可以建立一個模型,讓這個模型自己找出資料的特徵,於是深度學習就出現了。透過一連串神奇的操作後,特徵就自己跑出來了,而常見的技術就是 CNN, DNN。
關鍵名詞解釋
卷積神經網路(Convolutional Neural Network, CNN):是 YOLO 應用的主要技術,透過 CNN 先找出符合的物體,之後再判斷哪一區域有符合的物體,且機率最高,即將該區域以方框標註。以下大致描述一下 CNN 的內容。
卷積神經網路由一個或多個卷積層 (Convolutional) 和頂端的全連通層 (full-connection)(對應經典的神經網路)組成,同時也包括關聯權重和池化層(pooling layer)。這一結構使得卷積神經網路能夠利用輸入資料的二維結構。與其他深度學習結構相比,卷積神經網路在圖像和語音辨識方面能夠給出更好的結果。下圖就是 YOLOv3 用來萃取特徵的 darknet-53 的 53 層 CNN 網路,其中的 Residual 指的是殘差層,主要是用來避免網路層數過多而造成的缺點。卷積神經網路(例如Alexnet、VGG網路)在網路的最後通常為 softmax 分類器。微調(fine-tuning)一般用來調整 softmax 分類器的分類數。例如原網路可以分類出 2 種圖像,需要增加 1 個新的分類從而使網路可以分類出3種圖像。微調可以留用之前訓練的大多數參數,從而達到快速訓練收斂的效果。例如保留各個卷積層,只重構卷積層後的全連接層與 softmax 層即可。
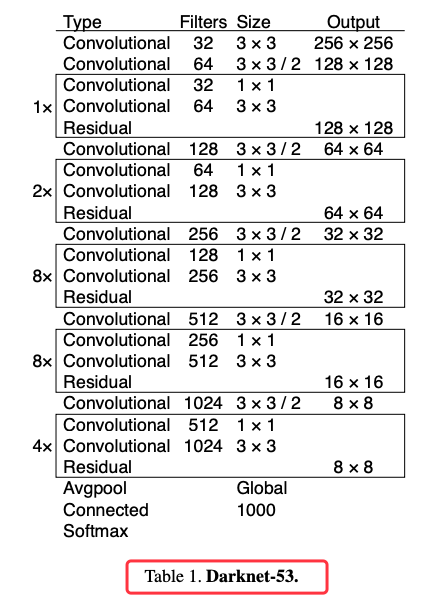
圖 1、YOLOv3 的 darknet53
卷積層:是一組平行的特徵圖(feature map),它通過在輸入圖像上滑動不同的卷積核並執行一定的運算而組成。
池化層(Pooling):它實際上是一種非線性形式的降採樣。
激勵層:線性整流層(Rectified Linear Units layer, ReLU layer),主要可以增強判定函式和整個神經網路的非線性特性,而本身並不會改變卷積層。
完全連接層:最後,在經過幾個卷積和最大池化層之後,神經網路中的進階推理通過完全連接層來完成。
期 (epoch):1 個 epoch 等於使用訓練集中的全部樣本訓練一次。
批次尺寸 (batchsize):一次訓練的樣本數目。
細分 (subdivisions):一次批次可以細分成幾次放入記憶體內。
迭代 (iteration):一個 iteration 等於使用 batchsize 個樣本訓練一次;
epoch=(全部訓練樣本/batchsize)/iteration
舉個例子,訓練集有 1000 個樣本,batchsize = 10,那麼訓練完整個樣本集(1次epoch)需要:100 次iteration。
1 = (1000 / 10) / 100
而通常在調整參數時,batchsize 是可以被調整的,考量的基礎如下:
1.通過並行化提高記憶體利用率。
2.單次 epoch 的迭代次數減少,提高執行速度。
3.適當的 batchsize,可以使梯度下降方向準確度增加,訓練震動的幅度減小。
但明顯的是 batchsize 的大小是跟記憶體相關的。
下圖是根據 YOLOv3 的論文中擷取出來的圖片,只能說這是給天才看的,我這個凡人實在無法想像,把關鍵線條畫在圖表的左邊是什麼意思,執行時間是負的嗎?因此,又找了一張圖,是 YOLOV4 的作者畫出來的,比較人性化了,可以發現 YOLOV3 速度是夠快,但精準度似乎有點差強人意,這是在 Nvidia V100 的 GPU 運算速度。現在我們需要理解的就是,何謂 mAP。
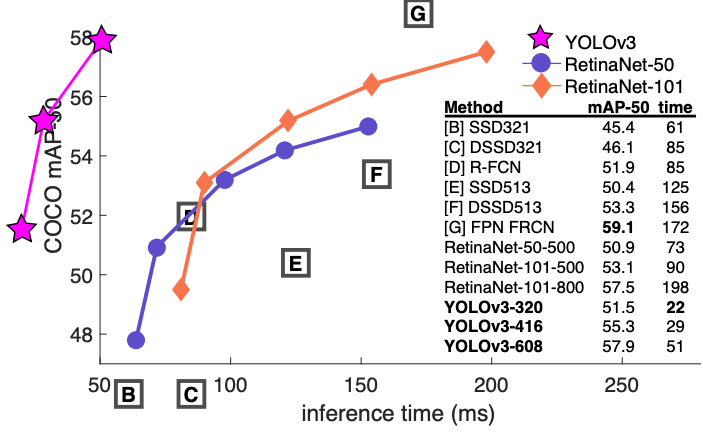
圖 2、YOLOV3與多種影像辨識模型在微軟的COCO資料集的效能表現
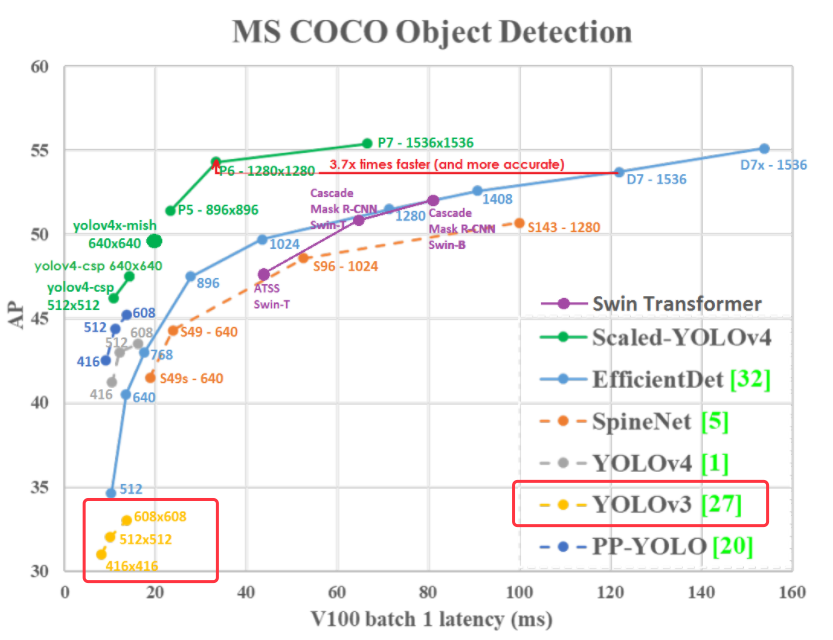
圖 3、多種影像辨識模型在微軟的COCO資料集的效能表現
預測結果可以細分為:
上述各中情況將分別簡寫為:TP, FP, TN, FN。因此:
根據上方情況,定義出以下的衡量指標:
物體偵測除了要判斷影像中的所有物體各自屬於哪個類別之外,還要找出物體的位置。可想而知模型的好壞不能只單靠準確率來做判斷,因此我們需要其他評估方式來判定模型的物體偵測能力。
Intersection over Union (IoU)
$IoU = \dfrac{Area of Overlap}{Area of Union}$
IoU 的概念還滿簡單的,就是評估預測的方塊框 (bounding box) 與 真實的方塊框 (ground-truth bounding box) 是否重疊的指標。一般情況下,如果預測的方塊框被預測為確實有目標物存在,而且 IoU ≧ 0.5 (此 threshold 會依情況有所調整) 我們就認定此 bounding box 為 TP (True Positive),反之則為 FP (False Positive)。根據這個判斷可以算出 Precision 跟 recall,而 AP (Average Precision) 就是計算 Precision-recall curve 底下的面積。詳細的計算可以參考 mean Average Precision (mAP) — 評估物體偵測模型好壞的指標。
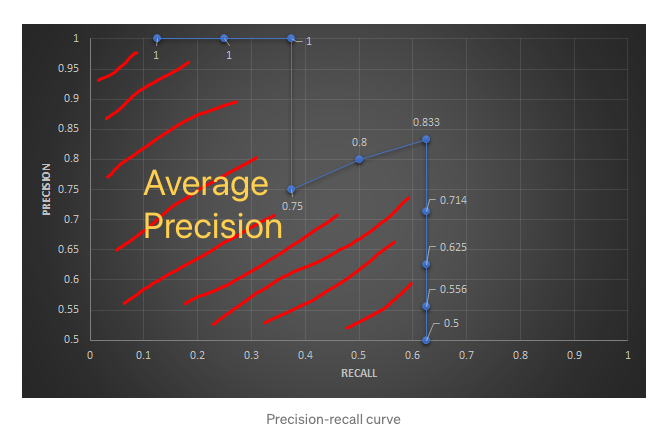
圖 4、Average Precision的計算
mean Average Precision (mAP) 指的應該是當我們計算每一個類別的 AP 之後再作平均就會得到 mAP。以coco數據集來說,它有 80 個類別。

